
Google???????????? Baidu????HOLD???
???????????? ???????[ 2012/8/13 10:35:03 ] ????????
????Google??????SVP Amit Singhal?????????糿?????????????Google??Knowledge Graph???????????????????????????????????????汻???????????????????????
????????Google??????????????????????????????????????????????????????????????????????Knowledge Graph??Google????????500????????????????????3.5???????????????????????????浽??????С???Щ???????????????????????????????????????????????????????????????????????????????
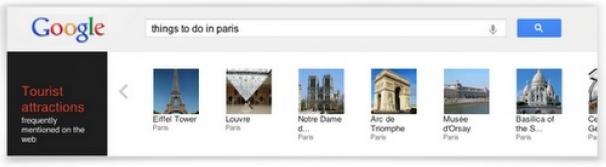
????Knowledge Graph??????????Google??Pregel??δ??????檔??ε???????????????????????????????????????У??????????????????????????????????????????????κλ????????????????????????????Knowledge Graph???????????
????????????????Gravity Labs????θ????????????臨?????
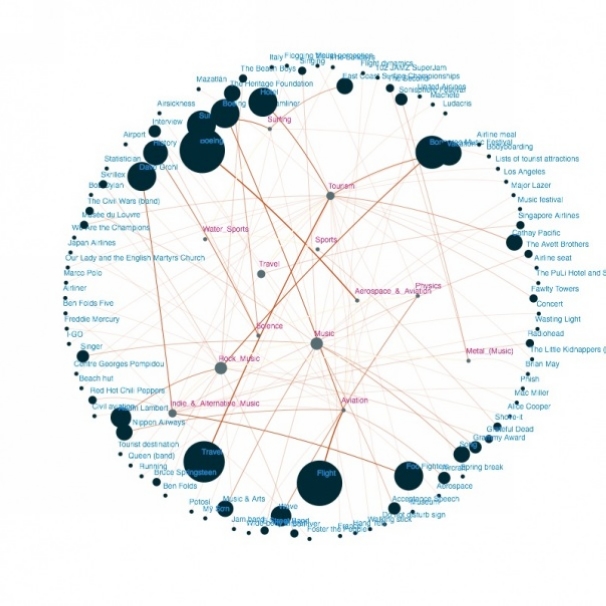
???????Google????????????????????????????????????????????????л?á???Singhal ??5?·???????·Knowledge Graph????????????????????????????????????????????????????????????????????????????????????????????????Tom Cruise????????????????????????37%???????????????
????Google??ε?????????????????豸????????????????????????а?????Android??iOS????????Singhal???1?????????
??????????????????????????????????????????????????????????????????????????????????????????????????????????????Google????????????????????????嵥?????????????????????????????Google??????????????????????????????
????Google?????????????о?????й??????????????????????????????????????е???Ц??????????????????????Android?????????????17???Brittany Wenger?????????????GAE???Global Neural Network Cloud Service for Breast Cancer?????????????????
????????????????Google??Microsoft??Apple??????????????????????????????????????????????С?豸???????????????????????????????????????????????????????м??????????????????????????????????????????????????????????????????
??????











???·???
App??С????H5?????????????????Щ??
2024/9/11 15:34:34?????????????????????????
2024/9/10 11:13:49P-One ???????????????????????????????????????
2024/9/10 10:14:12???????????????????????????
2024/9/9 18:04:26??????????????????
2023/3/23 14:23:39???д?ò??????????
2023/3/22 16:17:39????????????????????Щ??
2022/6/14 16:14:27??????????????????????????
2021/10/18 15:37:44
 sales@spasvo.com
sales@spasvo.com